I benchmarked 15 leading AI models on controlled project-controls tasks, and the spread between them is large enough that it should change how we talk about "using AI" in scheduling.
Each model answered the same unaided schedule-analysis problems: critical path, float, DCMA-14 logic, statusing, and earned value. No calculators. No external tools. No schedule engine access during the answer.
The important part: every answer was checked against objective, arithmetic results from a deterministic scheduling engine.
These were calculable outputs, critical path, float, dates, variances, and earned-value numbers, not subjective opinions about whether an answer "sounded right," and not what we hoped the model understood. It was model output compared directly against computed ground truth.
Takeaway 1: The model you choose materially changes reliability.
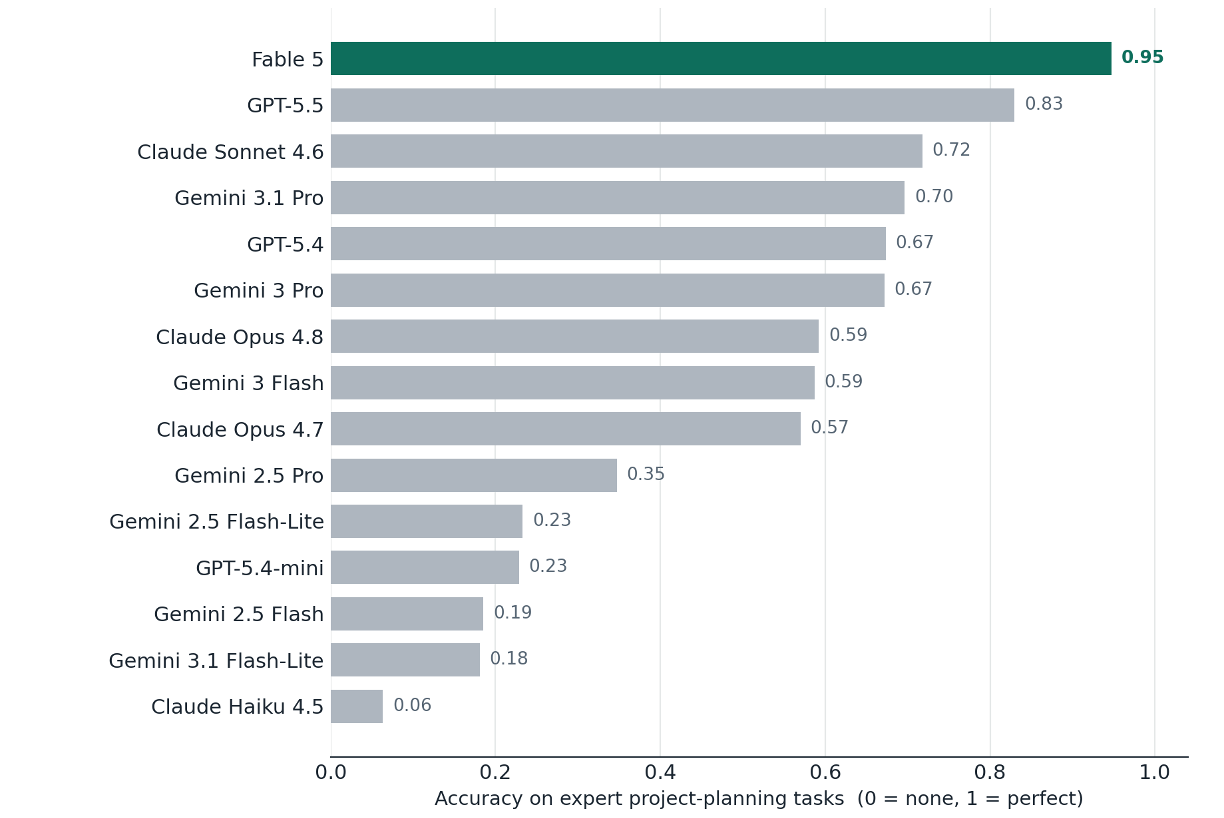
Chart 1 shows the main schedule-analysis leaderboard.
- The top score was Fable 5 at 0.95. I have confirmed that result across three internal runs using the same objectively graded battery and the result was stable across those runs.
- Among the established frontier models, the spread is also meaningful. ChatGPT-5.5 scored 0.83, while Claude Opus 4.8 scored 0.59 on the same benchmark.
- Several lighter models landed below 0.25.
That matters because "we use AI" tells you almost nothing in project controls.
Which model you use is the real decision.
Takeaway 2: The best schedule reasoner is not always the best optimizer.
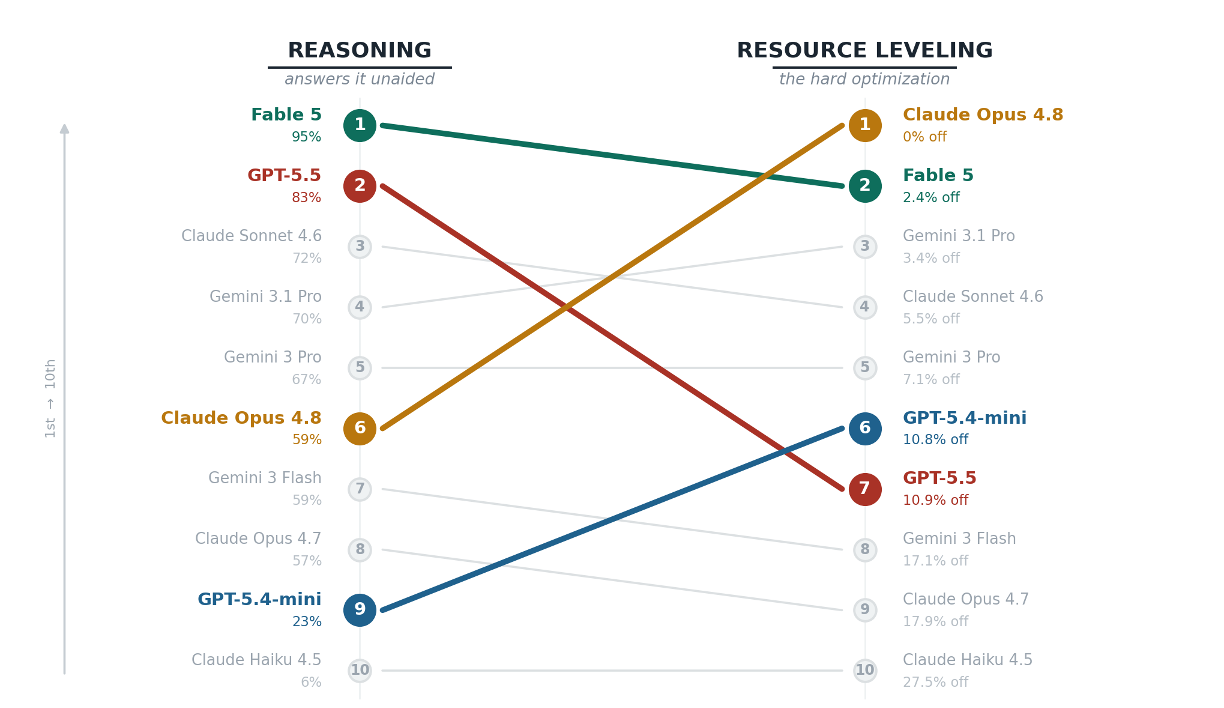 Chart 2 compares unaided schedule reasoning against tool aided (single shot) resource-constrained optimization / leveling (RCPSP) performance. (This would be similar to when you use ChatGPT or Claude chat capability - Models usually code for complex tasks!)
Chart 2 compares unaided schedule reasoning against tool aided (single shot) resource-constrained optimization / leveling (RCPSP) performance. (This would be similar to when you use ChatGPT or Claude chat capability - Models usually code for complex tasks!)
This is where the result gets more interesting.
- Claude Opus 4.8 was mid-pack on the schedule-reasoning leaderboard, but ranked first on the resource-leveling test, hitting the proven-optimal answer.
- ChatGPT-5.5 showed the opposite pattern: very strong on reasoning, but much weaker on resource leveling.
- Fable 5 was the only model that stayed near the top across both views.
That is the practical lesson "best AI model" is not a universal label. It depends on the job.
The model I would use to draft or challenge a delay narrative is not automatically the model I would trust to reason through an optimization problem.
And even then, resource leveling is exactly the kind of work where I would still want engine-backed verification before treating the answer as reliable.
My conclusion
My takeaway is neither "AI can do schedules" nor "AI cannot do schedules."
It is this:
AI is useful for schedule-analysis support, but model choice and verification are not optional, and it comes almost always with an additional cost.
- I would use top-tier AI for first-pass reasoning, narrative drafting, explaining a DCMA flag, and initial schedule logic review (on small, clean schedules).
- I would not treat a general chatbot as the system of record for schedule, earned-value, or resource-leveling numbers without a trusted engine-backed verification.
- A float calculation, SPI(t), or leveling result can look polished in a report and still be wrong.
Simply "Using AI" is not a strategy.
Choosing the right model for the right task, knowing where it fails, and verifying the arithmetic is the strategy.
Independent research; views my own.
------------------------------
Zine Eddine Zouaghi
zine.zouaghi@gmail.com------------------------------